
One of the crucial aspect of our professional podcasting platform is providing accurate statistics to our hosts. That’s always been one of our top priorities, and that’s why we built our own IAB certified data platform. As you may imagine at Spreaker we perform a great amount of data aggregations every hour, that has been growing both in volume and diversity over time.
Part of this data is exposed to our users through the Spreaker CMS. Meaning that data should be accessible through a set of fast public APIs.To achieve this goal we built a set of REST api on top of a read optimized AuroraDB database.
In this post we will take a look at AWS Step Functions, and how we ended up using them to populate our AuroraDB database to overcome limitations we had using plain Serverless lambda functions. Let’s start from the basics!
Are you passionate about AWS Lambda, Node.js and Serverless?
What are Step functions?
In essence Step Functions allow you to define a state machine and execute it on demand. You define the state machine using “Amazon States Language”
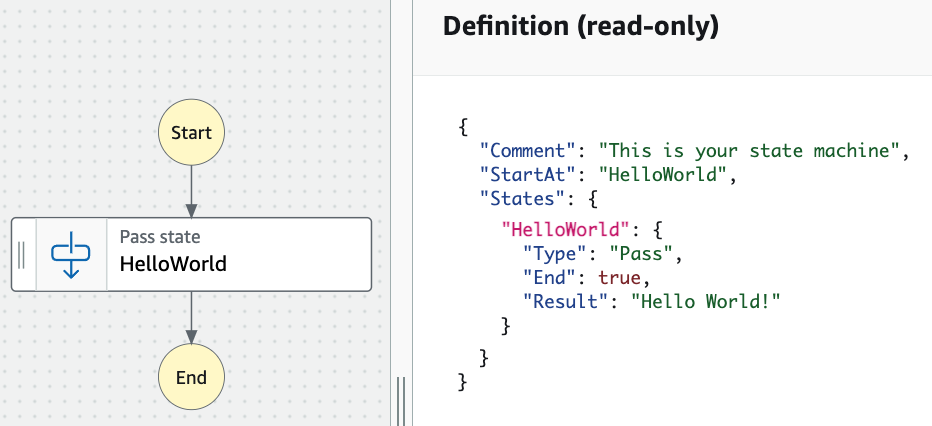
The definition of the State Machine is done using JSON. A tool called “Workflow Studio” is now offered, that will allow you to define the state machine in a graphical way instead. Then the definition will be generated for you.
There are 2 mandatory fields in the state machine structure. The field “StartAt” that indicates which will be the state to start the execution from and the field “States” that is a collection of the states’ definitions.
The execution starts at the state referenced by the “StartAt” field and follows to the state referenced by the “Next” field present in the current state. This is repeated until a terminal state is reached. In this example the “HelloWorld” state is a terminal state because it sets the “End” field to true.
State types
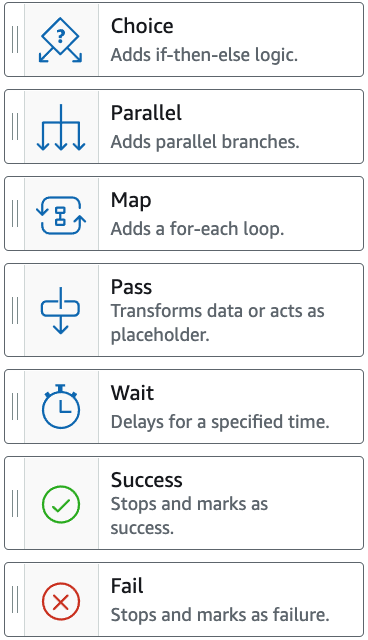

Each state definition requires a “Type” field. There are 8 types of states.
The “Task” type is the most useful one as it will actually execute some work. For example it allows to invoke a Lambda function execution. Support for calling more AWS services is constantly being added.
The “Success” and “Fail” are called terminal states as they immediately stop the state machine’s execution. Also any state with “End” set to true will be considered a terminal state. For more about state types check here.
Data flow
One of the most important concepts about Step Functions is how the data propagates between states. The white boxes in the picture are the existing data transformations you can define inside a state and their application follows the depicted order.
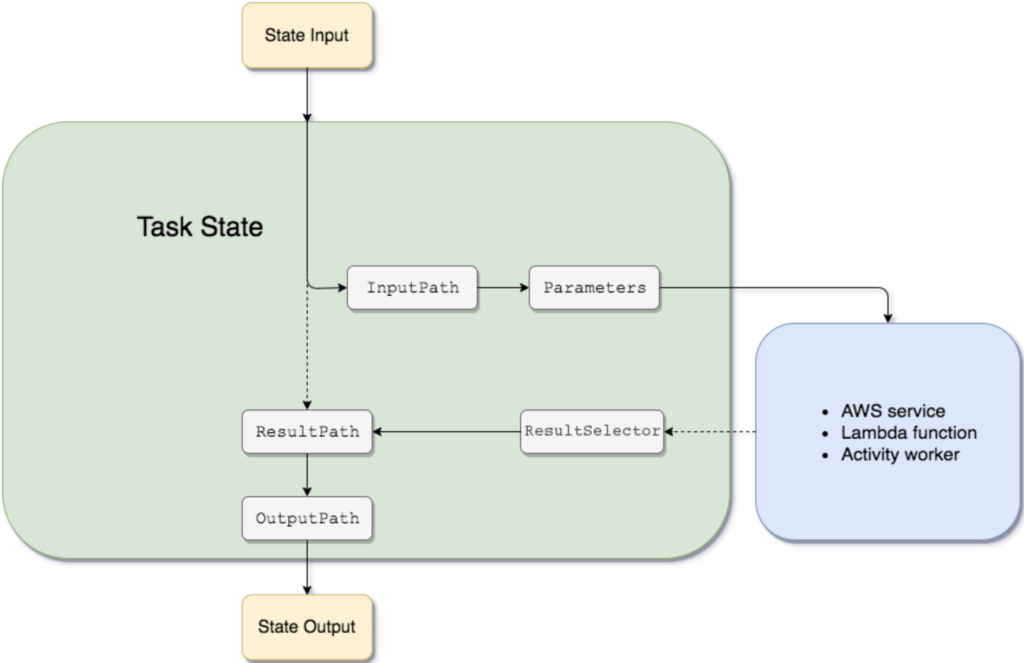
You can see it in action by playing with the Data flow simulator
Error handling
During state execution errors can be thrown. Step functions provide 2 options to handle an error:
- A self managed retry mechanism in which we define on which errors to act, how much time to sleep before retrying and how many times should the action be retried.
- A fallback mechanism in which we define which errors to catch and what state should be executed next. You may apply some data transformation before executing the next step.
Read more about it here.
Importing data from S3 to AuroraDB.
Now that we covered the basics of step functions let’s go back at the problem we are trying to solve (importing data from S3 to AuroraDB) and let’s take a look at an initial implementation.
The first implementation
A Step Function (called “importFromS3ToAurora”) is responsible for importing our data aggregations, produced in EMR into AuroraDB. This Step Function is invoking a Lambda function to do the actual work and the benefit of having it is the error handling. For example, Lambda functions have a hard limit for its execution of 15 minutes and when reached, the execution gets terminated.
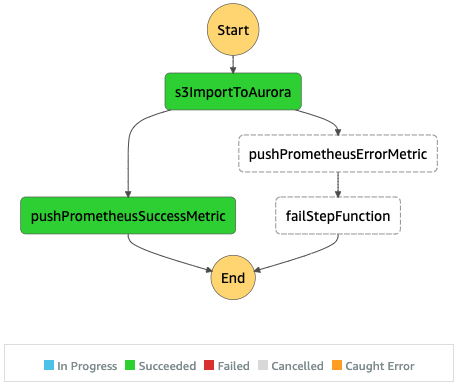
Issues with the first implementation
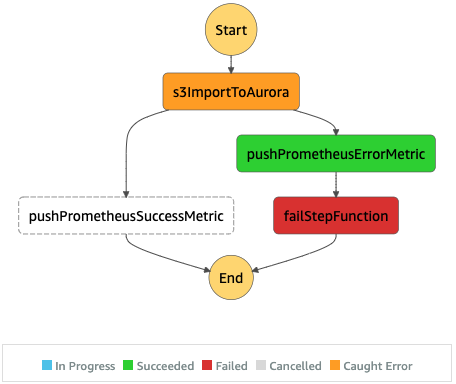
In our production scenario we need to deal with many concurrent executions of this Step function. We noticed pretty early that the bottleneck of this process is the access to the Aurora database. We need to keep its pressure under control while importing the data. The only mechanism available with this implementation was limiting the number of concurrent lambda executions and for the most of it that is enough.
What was done to improve
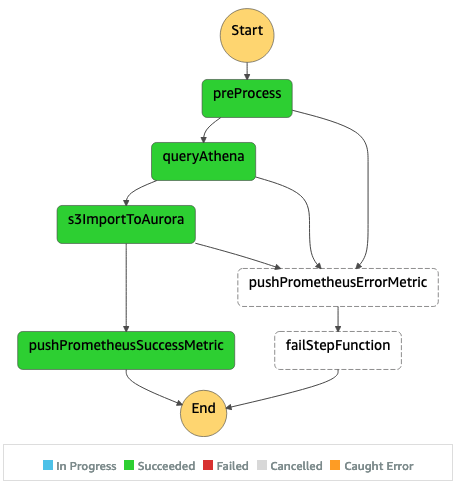
To reduce the pressure on AuroraDB we decided to offload the querying of the data to import, handling it to Athena service. For that, we’ve created a new “Task” state (“queryAthena”) that calls Athena service telling it to execute a given query and specifies where to store the result. The Lambda function executed by step “s3ImportToAurora” then loads the query result and imports the data into AuroraDB.
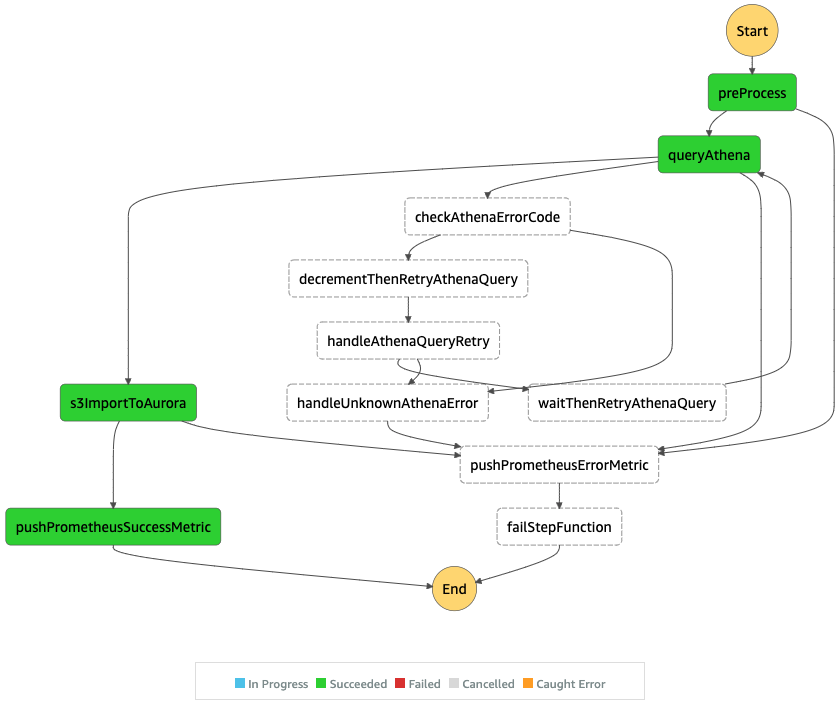
Custom Retry Mechanism
It’s very convenient to use the Step functions’ retry mechanism, but it has its limitations.
For instance we have no external visibility (except analyzing the execution logs) about failures if the retry mechanism is handling them, so no way of logging or pushing metrics.
In this particular case, when the call to Athena service fails, we get the error “Athena.AmazonAthenaException” and more details in an extra field called “cause”. The retry mechanism can match only on the error field, so there was no way to match the error cause and we had to build a custom retry mechanism.
The Orchestrator
Offloading part of the workload to Athena helped reducing the pressure on AuroraDB, but unfortunately it was not enough for our needs. As mentioned before, the only mechanism was limiting the number of concurrent lambda executions trying to import data into AuroraDB, however, there are some heavy tables that when concurring with each other will fail to import.
For that reason we decided to create another Step function (“orchestrateAuroraImports”) to orchestrate the imports. This new Step function will receive 2 lists of tables to import and for each table will start an execution of the “importFromS3ToAurora” Step function.
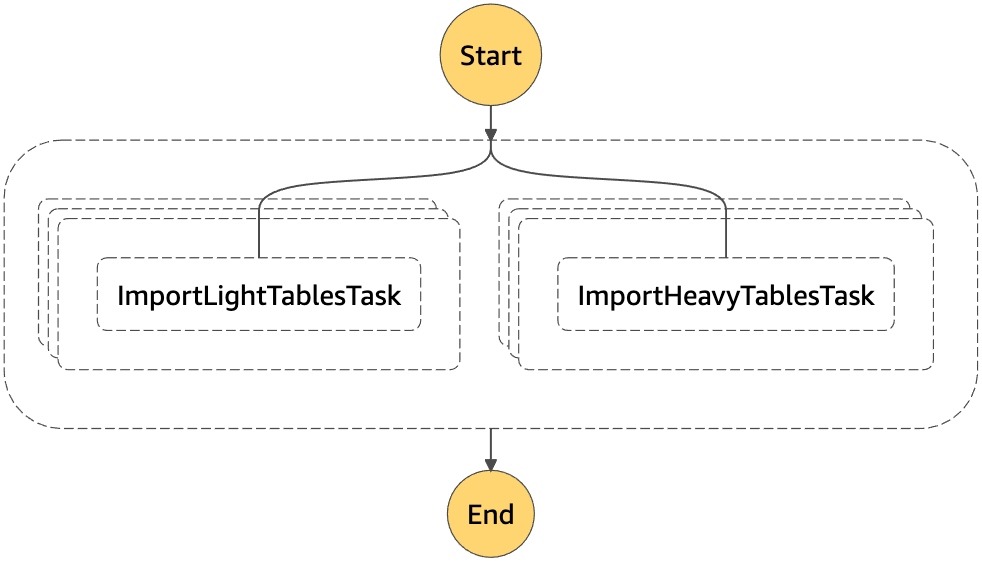
In the picture we see a “Parallel” state with 2 branches. Each branch has a “Map” state that iterates over a list of tables to import. The only real difference between them is that for the heavy tables we set the Map’s “MaxConcurrency” to 1.
Final notes
Step functions are very useful to orchestrate serverless workflows. Integration with other AWS services is constantly being added, making it very powerful.
If you’re starting to play with Step Functions we recommend you to use Workflow Studio, as it’s pretty intuitive and besides allowing to build the workflow in a visual manner has the benefit of showing you all the options available for a given state.
Another useful tool to use while developing is the Data flow simulator, when clarification about data transformation is needed.