
IP geolocation is a common technique to get physical location characteristics of a web visitor starting from the client IP address.
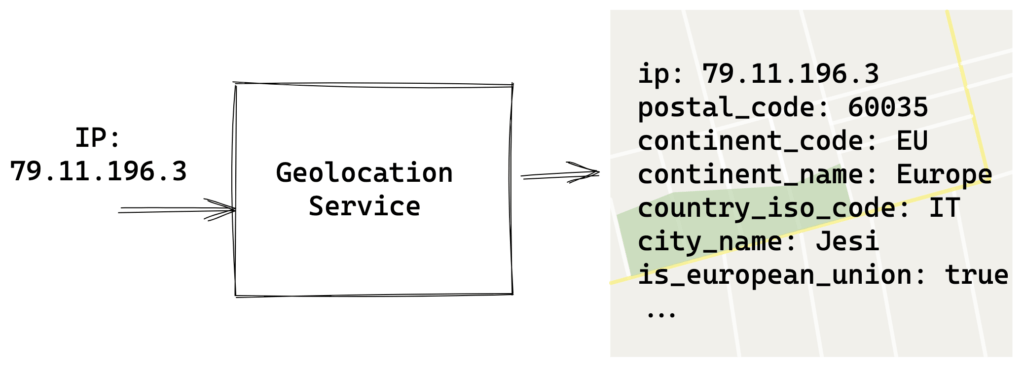
There’s a lot of reason why you would need a geolocation service, some of the most common are:
- Content Geofencing (this podcast can be listened to only from a certain country)
- Features Geofencing (this feature is only available to US users)
- Advertisement Targeting (this ad should be delivered only for podcast listeners located in New York)
- Performance Optimization (an HTTP request could be served from a location as near as possible to the client)
These are just some examples, based on our experience but there’s plenty more you can think of.
Are you passionate about AWS Lambda, Node.js and Serverless?
In this series of articles we will see how we implemented a performant and cost effective geolocation component for one of our AWS Lambda based component of our AdTech stack using DynamoDB.
The Problem
We will talk about our Yield Optimizer, a meta SSP we built to get the best audio AD spot available connecting dynamically a single podcast listen to as many as possible relevant audio spots marketplaces. To understand what we are talking about take a look at these simplified architecture charts:
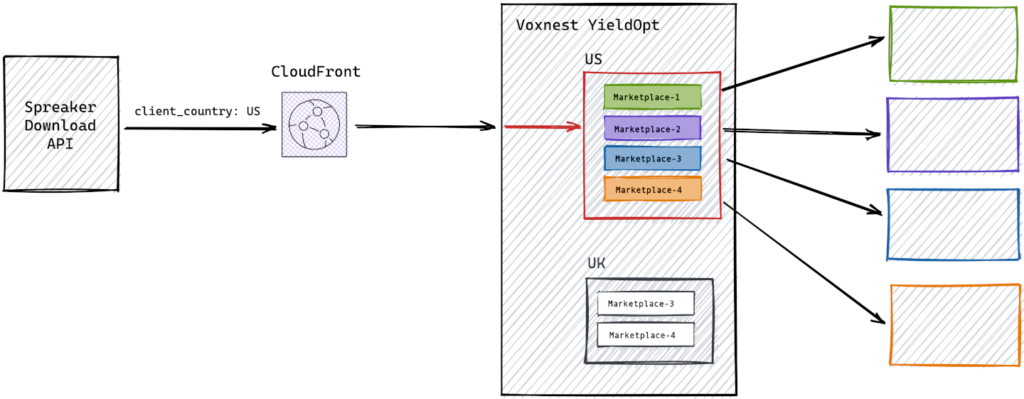
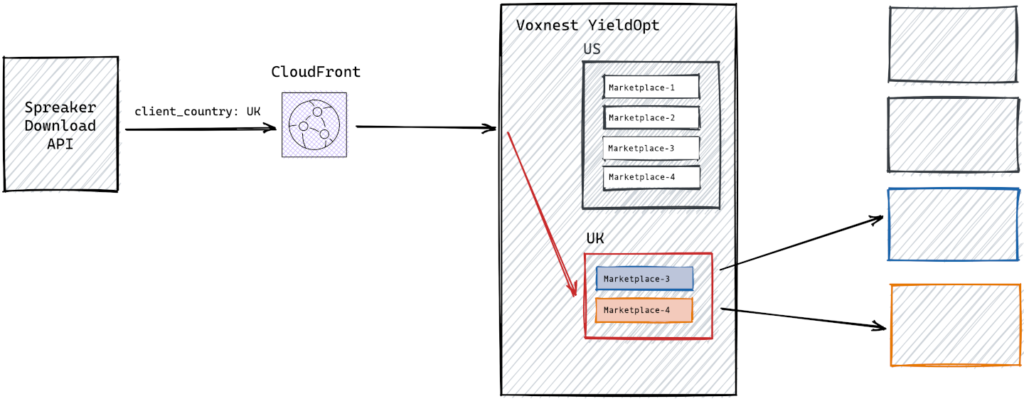
In our first iteration what you see as client_country was provided to the our yield optimizer lambdas in a stateless fashion. We controlled the caller so we removed from our serverless code the responsibility of doing the geolocation work.
This served us very well for a very long time, up to the moment when we had to expose directly the our yield optimizer APIs to clients we did not have any control of. We needed to do so without asking the caller to take care of the geolocation for two important reason:
- Simplify the implementation for the integrator. They don’t need to take care of providing a location.
- Do not rely on untrusted, and maybe not updated, geolocation data coming from a third party.
The first try
With this in mind the first solution we tried to implement was super simple. Since we have CloudFront in front of our APIs we can leverage what comes for free! CloudFront headers to the rescue:
https://aws.amazon.com/about-aws/whats-new/2020/07/cloudfront-geolocation-headers/
CloudFront-Viewer-Country-Name: United States
CloudFront-Viewer-Country-Region: MI
CloudFront-Viewer-Country-Region-Name: Michigan
CloudFront-Viewer-City: Ann Arbor
CloudFront-Viewer-Postal-Code: 48105
CloudFront-Viewer-Time-Zone: America/Detroit
CloudFront-Viewer-Latitude: 42.30680
CloudFront-Viewer-Longitude: -83.70590
CloudFront-Viewer-Metro-Code: 505You can activate this feature with just a click on your CloudFront distribution and start using them in minutes.
This is a fine solution but comes with limitations that made it not viable for us:
- CloudFront does geolocate on the socket IP so it does not work in a Server to
Server scenario and that’s what we needed. - Sadly, there’s at the moment no way to instruct CloudFront to perform geolocation on X-Forwarded-For and X-Device-Ip http headers.
The second try
Given the constraints we moved to another simple approach. Embedding the MaxMind geoip database in our lambdas ad use a library to perform local in memory lookup with a battle tested Node.js library:
This solution came with it’s own set of limitations and problems that we found along the way:
- The full commercial database is a big file (50 MB gzipped) and AWS lambda runtime is limited to 250 MB unzipped, including layers
We managed to keep the entire package inside the limits, we were ok with the trade-off of loading the DB in memory and having a bigger ram usage for our lambda. The problem we saw was an increase in cold start time due to a bigger package and bad I/O performance when loading the whole database in memory for the first time. The best we achieved with this strategy was around 6 seconds on a cold lambda.
The third try
To work around the I/O performance issue we tried yet another strategy, exporting the geoip database in SQLite format. SQLite does not need to keep the whole DB in memory to perform queries.
- Even with optimization tricks we didn’t find a way to pack the full MaxMind database in something smaller than 250MB unzipped
We tried to go around the limitations using a the new AWS Lambda container images (https://docs.aws.amazon.com/lambda/latest/dg/images-create.html) that allow a max size of 10 GB but we did hit other issues:
- Container images are very slow in cold start (we went from < 300ms cold start time to 7s)
- We took in consideration playing with provisioned concurrency https://www.serverless.com/blog/aws-lambda-provisioned-concurrency to keep the lambdas warm and minimize the cold start effect but the reality is that when you deal with irregular traffic spikes it become tricky to adjust dynamically the parameters to optimize for cost reduction.
Accepting the defeat

At this point we decided that we needed a standalone fast and cheap storage to query for geolocation data. We do have a lot of experience with Redis but we decided to evaluate DynamoDB and we came up with a little comparison of pros and cons:
Redis
- PROS
- Fixed pricing
- Pretty simple to operate
- Performant (<1ms)
- We already use it
- CONS
- We always pay for it, even when there’s little use
- Needs to be operated and scaled
DynamoDB
- PROS
- Pay as you go
- No operational cost
- No peak performance headaches
- CONS
- Performance (5-10ms)
- Never used before
- Pay as you go is nice, but we had no idea on how much 🙂
After analyzing the scenario we decided that for our use case the query performance of 5-10ms on dynamo were ok, so the only unknown to tackle was about pricing, and specifically on the read path.
| Charge Type | Price |
| Read request units | 0.25$ per million read request units |
Read request unit: API calls to read data from your table are billed in read request units. DynamoDB read requests can be either strongly consistent, eventually consistent, or transactional. A strongly consistent read request of up to 4 KB requires one read request unit. For items larger than 4 KB, additional read request units are required. For items up to 4 KB in size, an eventually consistent read request requires one-half read request unit, and a transactional read request requires two read request units.
https://aws.amazon.com/dynamodb/pricing/on-demand/
In our case it was perfectly fine to have eventually consistent read and we were comfortable with an estimate spend of around 2.5 $/day for our baseline of 20M req/day. Given that we can keep each dynamo db read query under 4KB.
In the upcoming part 2 we will see how we structured our data on AWS DynamoDB to ensure the desired Consumed Read Capacity Unit of 0.5.