
Spreaker is a podcasting platform that has been around for more than 10 years. In such a long time span pretty much everything has changed.
- Core Features
- Scale
- Business Goals
- Team Dimension
- Internal Organization
- Technology
This is very common in any thriving software business. From one point of view is absolutely something to celebrate. From another side, it comes with a very broad set of challenges.
Codebases that deliver value for such a long time have the tendency to go in a way that what we like to describe internally as “The Rotten Fruit Effect”.
Introducing “The Rotten Fruit Effect”
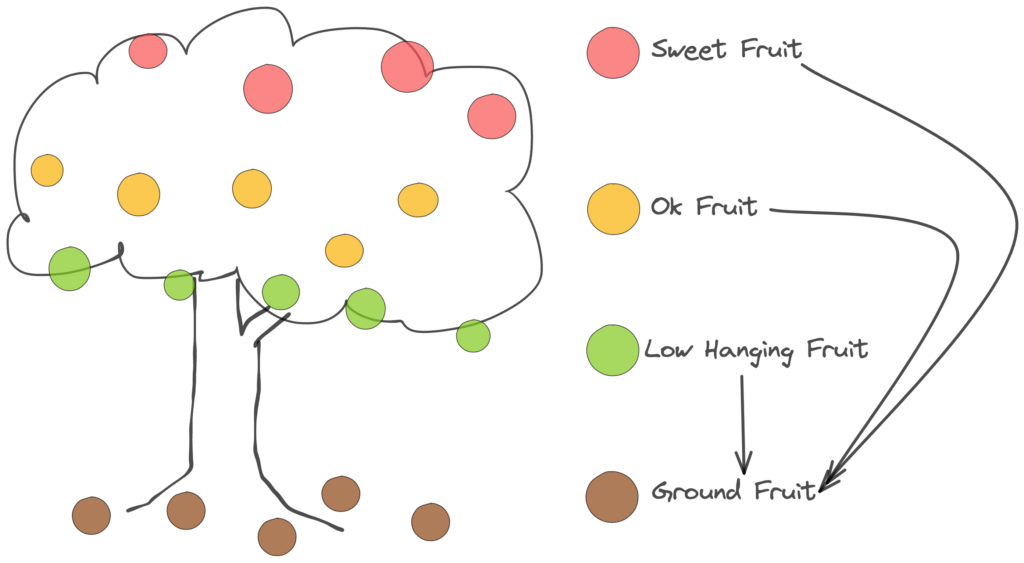
Think about our product as a Tree, and the fruit as the yield that we can collect from it.
- Sweet fruit: they are the best of the best, they sit at the top, the get most of the sunlight. They are very difficult to pick.
- Ok fruit: they are a little more juicy then the low hanging ones because we pick them less frequently, they are a little bit more difficult to reach
- Low hanging fruit: we just love them, they provide very good value with very low effort
- Ground fruit: they are sitting on the ground, very very easy to pick. Most of them are completely useless since they are rotten.
With time passing we naturally tend to just focus on low hanging fruit, without investing in tool necessary to reach the ok and the sweet ones. The sad reality is that there’s a little amount of low hanging fruit and if we don’t do anything to reach the top we end up just with poor quality ground rotting ones.
What kind of efforts provide us the ability to catch sweet fruit?

Building software that enables the organization to get the best fruit means carefully prioritizing efforts that have the following intrinsic values:
- They unlock additional value that can be built on top
- They prevent disruptions and disasters
- They enable future options and opportunities
If we had to synthesize it with a single concept we can think about all the efforts that are basically investments in the future.
Is it something simple to do?
Nope, is not. The harsh reality is that these efforts are usually the trickiest one for an Engineering team. The common things that you can expect from these in a consolidated long running business are the following:
- They are usually very long sustained efforts
- It’s pretty common to lose track of the progress
- They will create discomfort if the expectations are not set correctly
- From time to time they may feel like a bottomless pit
- Even when planned carefully they will act like a moving target
To make those concepts a little bit more concrete we can give some examples of things we did in the last of year:
- We completely migrated millions of customers from a “Single User Based” experience to an “Organization Based” one to enable collaborations scenarios.
- We rebuilt from scratch our Podcast Delivery Network that serves more than 400 million episodes per month with reliable Dynamic Ad Injection and moved it completely to Serverless without any downtime.
- We moved our legacy internal business analytics tools to a third party platform without disrupting any internal workflow, and enabling unprecedented autonomy for our product teams.
- We rewrote from scratch our observability stack for all of our AWS lambda functions, reducing costs, and improving visibility and autonomy for our developers.
Before starting
With all the experience we gained, there are some basic things we think are very important to do even before starting working.

Assess the current state
A deep knowledge of the current state is necessary to start a long running effort. Spend all the time needed and involve people that have past knowledge about the current state.
If you are not able to assess the current state, we have a red flag. Stop the line, rinse and repeat.
Describe the desired state
What is the ideal state? What does the ideal state enable? Try and quantify the value that you want extract from the new status quo.
Tools we find useful for this kind of analysis
For those cases we usually try and write a concise document trying as much as possible visualization techniques such as diagrams and simple options analysis tables.
| Before | After | |
| Possible | See all the business metrics in our back office | Product teams can create custom aggregations |
| Easy | Keep costs under control | Specific analysis can be shared to external stakeholders Use predictive models Craft clear data visualizations |
| Difficult | Create new aggregations to satisfy business needs since they need development effort | Make sure that data models are not diverging between two system |
| Impossible | Product team can create custom aggregation | See all the business metrics in our back office |
| Risky | Give data access to external stakeholders | Costs must be kept under control (usage based billing) |
It’s important to understand that those artifacts don’t need to be extremely accurate. The value they provide is mainly in the process of writing and discussing them.
Another thing that usually provide value is trying to come up with a series of invariants and mantras. Things that must always remain true before, during and after the work usually acts like natural compasses. Check them regularly.
Anticipate the unknown
Another important thing that you should always do before starting for a long development journey is spending time thinking about possible roadblocks. These are the things we think are worth taking in consideration:
- Tackle hard problems first
- Execute Proof of Concept for hard problems
- Try and build low fidelity End 2 End prototypes
- Keep in mind that there are things that we cannot control
- Partners Management, Other Teams Dependencies, Legal Analysis, Customer Migrations are usually long and excruciating tasks. Start them as early as possible, otherwise they will become roadblocks
There will still be a category that can not be dealt with early, the unknown unknowns. There’s not a lot to do about those an in general is not worth spending time trying to anticipate everything.
Ready to start

We did a bunch of analysis, we are confident that we are going in the right direction and now is the time to start working. What do we do first?
Highest Return First
A good practice to start working on a long running task is trying to do first the things that will give us the highest return with the smallest effort. Yep, we are going for the low hanging fruit again, but this time in the context of a higher goal that is not. Why should we do that?
- In a long effort, the sooner you start collecting value, the more you will collect before the end of it
- Some early wins are the best way to remove pressure from the team, and start gathering real world feedback
- As much as it seems not needed, they help keeping stakeholders happy
In this context trying to make the return on effort investment measurable is a very important exercise. Sometime is not possible but most of the time it is and having it known will facilitate communication with various stakeholders.
The process

There are some things to keep in mind now that you are actually working on the project, and most of them revolves around four areas.
Progress Communication
Communicating the progress of an effort is as important as doing it. Doing it doesn’t mean writing down a shopping list of what you did last week and what yo will do the next one. It’s keeping people informed about relevant things:
- What was released in production and how does it impact the stakeholders
- Do we need some action from a stakeholder in order to unlock the next piece of software to be delivered?
- Do we expect a business/technical/operational impact after an item from the roadmap is delivered?
Scope Management
Scope creep during these kind of work is the hidden trap that is very easy to fall in. Trying to improve little things you find on the road that are not related at all may end in the classic death from a thousand paper cuts. It’s difficult to find a balance but you need to clearly decide what not to do. Remember that:
- Deciding what not to do is more important than deciding what to do. It prevents you to fall down the rabbit hole.
- Deciding what not to do is not an excuse to not refactor, not doing preparatory work or lowering the quality bar. It’s about excluding things that are not important and easy to postpone but require a sizable amount of effort.
- Deciding what not to do take as much deep analysis of deciding what to do, is not an excuse to not think about a problem.
Once you decide what not to do, stick to your decision. It’s very easy to forget it.
Rollout Management
Prepare a rollout plan before writing the first line of code for the current task. You need to be sure that you have a CLEAR understanding of how the current piece of work will reach production environment at every moment.
Time Management
Time management is a tricky topic. Is rarely super important but is usually treated as “the problem” when other things are not going well. Those are some key principles we try to follow:
- Don’t stress about time, be obsessed with value and scope.
- If we did the exercise to understand the ROI of the work, time and estimations are not a big deal.
- Still, clearly communicating release time is crucial. We try and do the exercise internally to understand when a piece of the roadmap will be released. Doing that is important to verify that we have a deep understanding of what we are doing.
The Reality

As much as we would love to say that following those principles will make the journey feel like a smooth sailing trip, this is simply not true. During the process, new informations will arrive, the scenario will change and at the end of the day there’s nothing we can do about it.
What we can do is embrace the reality, and deal with it.
Stuck in the Mud
Sometime during a long running effort things get stuck. When this happens there’s one main thing to do:
- Ask for help if you are the one in the mud
- Give help if you are seeing a coworker struggling
We have a lot of moments in our organizations just for doing that:
- One to One with engineering managers for personal struggles
- Retrospectives for difficulties in team dynamics
- Regular Engineering meetings for technical struggles
Having those safe spaces is very important to ensure that people are never abandoned while they are trying to achieve something ambitious and they get stuck.
Celebrate The Process

When we have a long path in front of us we may feel like is never time to celebrate. If you just celebrate the final result there’s an high chance that you will end up celebrating nothing at all.
We take the time to celebrate every release along the road that bring us near to the desired state.
The End Goal
Successful long running efforts will usually unlock more work. Nothing is ever done. This is perfectly normal and it’s a clear sign of a product that is worth continuing investing in.
If you reached a goal and there’s nothing more to do it’s a clear sign that you are near to the end of the product.
Embrace change!