
In the last episode of this series of articles we went through the experiments and road blocks that lead us to try and use DynamoDB to implement a geolocation service for AWS Lambda.
We closed the previous article with an open question:
How can we structure our data on AWS DynamoDB to ensure a desired Consumed Read Capacity Unit of 0.5?
Are you passionate about AWS Lambda, Node.js and Serverless?
What data are we storing?
In order to understand how to optimize our data storage for efficient lookup, we need to dig a little bit into what are we exactly storing. As you may imagine the MaxMind GeoIP database does not have inside all the possible IP addresses in the world but a sparse representation of IP ranges in CIDR notation.
That means that given an IP address there’s no way of doing a direct lookup on a key that gives us a guarantee of 0.5 read capacity units consumed.
We need some sort of function that we can use to associate uniquely an IP to query efficiently a sparse list of IP ranges.
Presenting INET aton(ip)
The aton function gives you an integer from an IP string.
inet.aton("125.121.234.1") => 2107846951
Ideally, if we store the MaxMind ranges with:
ips = aton(ip_range_start)
we could look for our GeoIP record like so:
ip => aton(ip) => ipn => query_reverse_scan(ips <= ipn) => geolocation 🎉
We need to remember though that DynamoDB is a key-value store. We cannot use aton(ip) and just do a direct access to the key…
DynamoDB key structure
We already know that Dynamo is a key-value store. You need a key to retrieve an object but there’s a concept that we can use and is how the key is composed:
- Hash Key mandatory
- Range Key optional
The hash key determines the partition in which data is stored. The range key determines the order in which records are stored inside the partition.
Leveraging this we can perform queries of this kind:
- Hash Key := VALUE
- Range Key <= VALUE
Bingo?
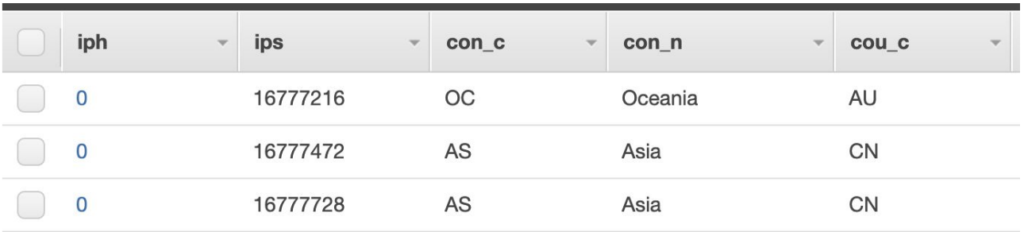
If we store the ip_range_start_number(ips) as Range Key we have a way to query for our data! In principle we could have:
- Hash Key: 0
- Range Key: aton(ip_range_start)
Not really…
If we store everything on the same partition key then we are actually doing a sequential scan every time we want to locate an IP. Read capacity consumed skyrockets depending on where the IP is located.
The next thing that comes natural is using the first triplet of the IP address as Hash key:
- 182.34.12.1
- 69.56.1.4
- 23.34.12.1
As much as this looks simple and promising, it will not work. IP ranges geolocation information are sparse, there’s basically very little geolocation information from:
0.x.x.x to 10.x.x.x
But there’s a ton of records, for example, in:
169.x.x.x
We want the partition key to isolate a constant number of records to have read performance guarantees.
How did we solved this?
We can actually decide an arbitrary strategy to generate our HASH KEY so that we can query with both the HASH KEY and the SORT KEY.
Experimentally we discovered that we can store 32 IP ranges per partition and keep the consumed read capacity unit at 0.5.
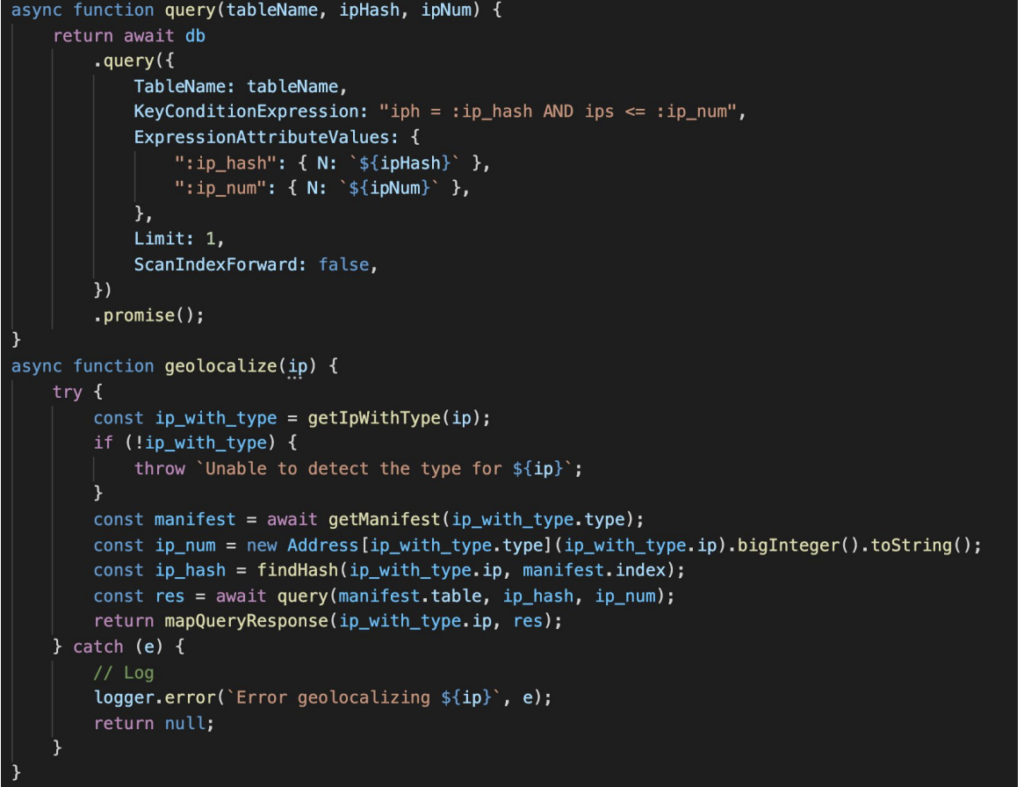
In order to do this we have to add a little bit of complexity on the caller since it can’t just query using data derived from the IP:
- aton(ip)
While preparing the data for DynamoDB we create an index that we put in a json manifest with all the IP start numbers of the beginning of each partition. The index of the array determines the HASH KEY we then have to use to query the database in an efficient way.

In order to find the HASH KEY required to query for an IP we can do a binary search on the manifest using the aton(ip):
- findHash(23) => 0
- findHash(16777218) => 1
- findHash(16799488) => 3
Now is just a matter of giving our Lambda functions visibility over the manifest file.
Where did we put the Manifest?
The manifest is pretty compact, we are talking about 1MB gzipped content. The most simple strategy is to just embed it inside the lambdas at deploy time. This comes with pros and cons:
Pros
- Very simple to implement
- Basically little to no impact on cold start performances
Cons
- Every time we want to rollout a new version of the MaxMind database we need to redeploy the lambdas with the manifest for the latest version
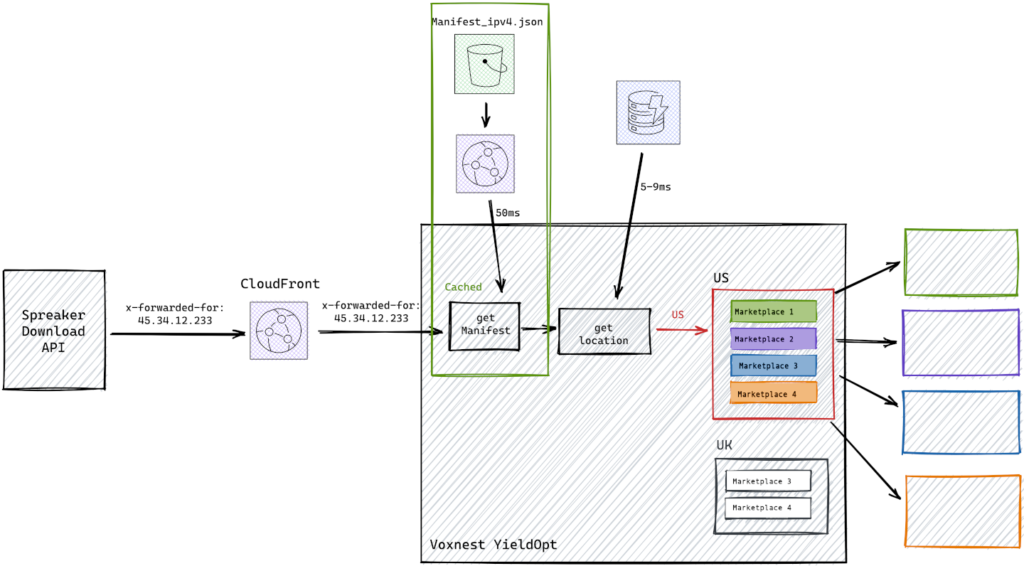
We decided to walk the extra mile. In our final solution, we download the manifest in a lazy manner on the lambda function, and we keep it cached for as long as the underlying container gets reused. That means being able to automatically rollout a new version of the GeoIP database without redeploying any serverless function that makes use of it.
This is the final architecture for our solution:
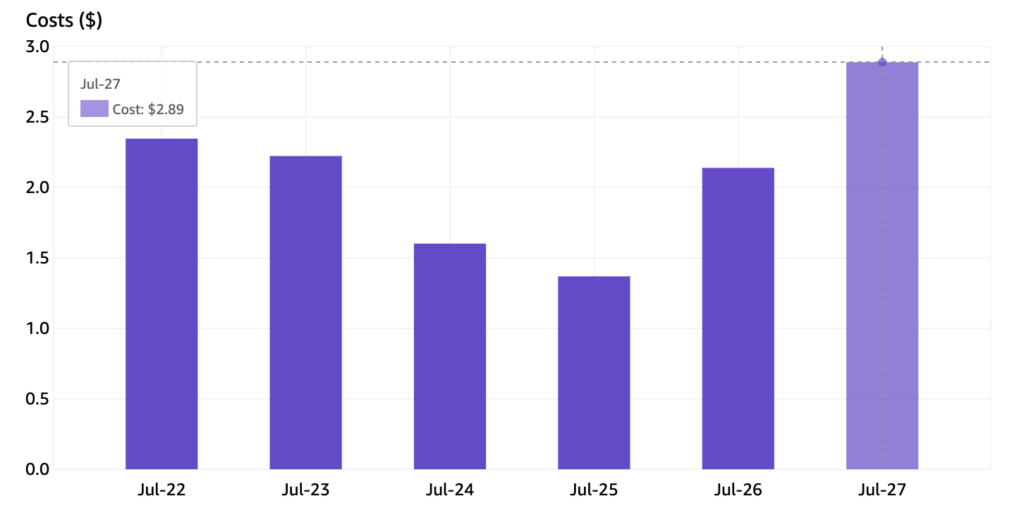
An these are the DynamoDB daily costs with full production traffic:
The whole project was pretty challenging and we learned a lot along the way but the main lesson is the following:
When you work with serverless solutions, try and start with a clear idea of the billing model in mind and what you are willing to spend for your particular feature. Once you have it clear it’s quite fun to architect your solution around it!